進撃の文系|殺されかけた語彙を、もう一度並べ直す|ヘイトスピーチ検出システム(α版)構築メモ
October 2, 2025
本稿は、筆者が経験した構造的ハラスメントに対処するために開発中の、そのハラスメントを記録・検出・可視化するシステムについてまとめたものであり、記憶されなかった暴力を構文単位で回収するものである。
「このシステムは誰のためにあるのか?」という問いに、私はこう答える:
これは、私のためにある。
画像の出典:https://www.reddit.com/r/Lain/comments/ylytj5/serial_experiments_lain_wallpaper_2560_1440/
私は元々、統計を学ぶことに怯えていた文系の人間だった。けれど、数えなければ誰も信じてくれない暴力の中に放り込まれ、私は生き延びるために数字の言語を習得し始めた。それは好きで始めたことではない。記録されなければ存在しない世界に対抗するためだった。
私は中国人で、英語が完璧にできるわけでもない。同人小説を書くだけの一個人にすぎない。だが anti-ygpgsgl のように1日20件以上の投稿を繰り返す「人格構造の暴力装置」に晒されたとき、私は誰も代わりに処理してくれないその暴力を、構文として解体し、記述する者になるしかなかった。
本システムは、筆者自身が構文的ハラスメントに晒された体験をもとに構築されているが、その前提には、筆者の物理的アクセス環境そのものが平等ではないという問題がある。
筆者は中国在住であり、Tumblr、AO3(Archive of Our Own)、X(旧Twitter)、Discordといった主要な創作・交流プラットフォームにアクセスするためには、すべてGreat Firewall(GFW)を越える必要がある。つまり、常に検閲のリスクを抱えながら翻訳し、投稿し、閲覧し、記録している。
一方で、筆者に対して集中的に攻撃を仕掛けてきたアカウント群は、英語を母語とし、上記プラットフォームへのアクセスが完全に自由である環境にいる。にもかかわらず、彼らは筆者を「AI使用者」「偽作家」として貶め、さらに中国語や中華的モチーフを用いて嘲笑することもあった。この構造は単なる言語の壁ではなく、構文的暴力が地理的・政治的アクセス差に依拠して強化されることを意味している。
投稿の中には、直接的な差別語や暴力表現は含まれていないものの、その文脈と使用対象を考慮したとき、明確な“追放機能”として働いている言語が存在する。
例:
-
"You need to go outside."
-
"Touch grass."
-
"Maybe stop being online 24/7."
これらは一見するとアドバイスや冗談のように見えるが、**翻訳不能な文脈に依存した“暴力的暗号”である。特に、筆者のようにGFWを越えてアクセスしている非英語圏のユーザーに対して、これらの表現は構造的アクセス差を無視した、“存在そのものの否定”**として機能する。
このような言語は、構文的ヘイトスピーチの一形態として明示的に記録する必要がある。
本稿は理解を求めるためのものではない。これは、理解されなかったときに備えて残す、言葉のログである。日本語ができても、理解されるとは限らない。暴力の構文を共有している人たちに、構文を説明することはできない。
🧠 システム概要
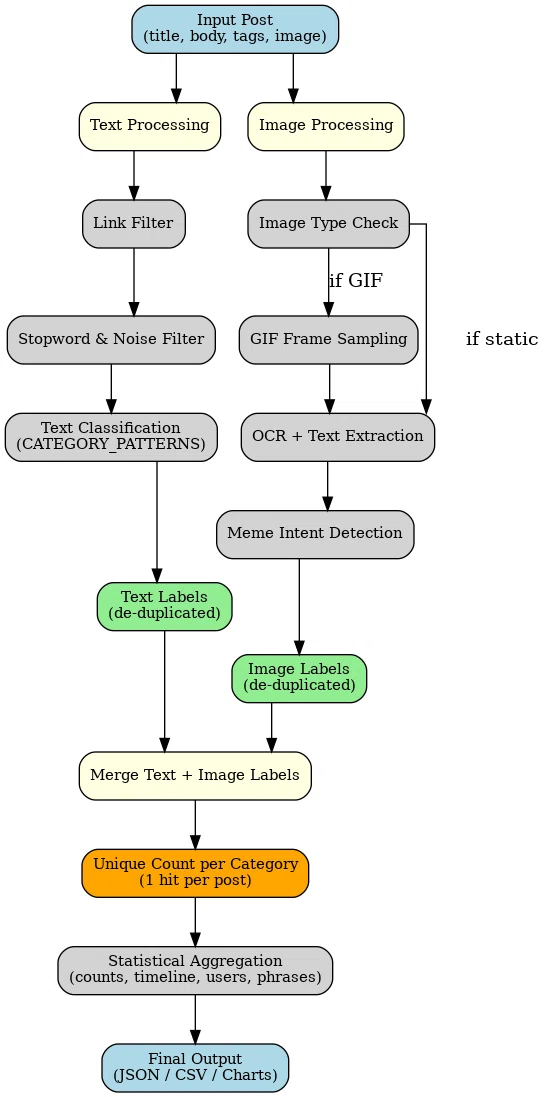
図 1:本システムの処理フロー概要
-
このシステムは、英語圏SNS上で発生する構造的ハラスメントに対し、投稿内容の視覚化・記録補助を目的として構築された個人向けプロトコルである。
-
実行環境はPython + OpenAI API。インプットはJSONログまたはスクレイピング結果、アウトプットは分類表・ビジュアライズ図表など。
-
検出対象:ヘイトスピーチ、人格攻撃、挑発絵文字、画像ベースの改変CGなど。
📘 構文フィルター判定基準
-
R-01 すべてのテキストは原則として嫌がらせ発言とみなす「これは嫌がらせか?」という無意味な判断を省略
-
R-02 頻度は見ない。構文パターンの一致だけを判定基準とする高頻度ではない攻撃性の高い言語を見落とさない
-
R-03 一度限りの構文でも記録対象とする攻撃的な意図を優先的に可視化。頻度に依存しない
-
R-04 主語の暗示を必ず追跡する(she / slut / bot などの間接攻撃も検出指示語・代名詞・スラングを用いた人物攻撃を捕捉
-
R-05 構造化された文を優先分類攻撃の構文特徴(動詞・命令形・主語述語構造)を出力
-
R-06 emoji・GIF・演出文(擬似ドラマ等)も攻撃材料として扱う「冗談」「ミーム風」などを装った攻撃を許容しない
🔧 モジュール構成
本システムは、投稿内容を①テキスト/②絵文字/③画像/④メタ情報 の4ルートに分けて処理し、それぞれのラベル判定結果を統合・集計する構造を取っている。すべてのモジュールは、共通の出力構造(JSON形式)に準拠して動作し、統計・可視化フェーズに向けて逐次送信される。
モジュール構成は以下の通り:
1. 投稿主体識別・引用構造解析(前提処理)
本システムは、いかなる処理モジュールよりも前に、投稿の出所(=誰がどのプラットフォームで発言したか)と、引用構造(=誰が誰の言葉をどう用いたか) を厳密に判定する。
理由:
-
被害者の発言が、加害者によって切り取り・加工され、逆に「攻撃の証拠」とされる事例が存在する。
-
SNS上における構造的嫌がらせは、往々にして**「引用の形をした人格攻撃」**から始まる。
本システムでは、スクリーンショットやリプライツリー、再投稿付きコメント等を解析し、各文の発話主体・引用元・改変の有無をトリプルで照合。
これにより、引用による誤認標的化や、無断加工による風評加害を見逃さない。
2. 投稿統合モジュール
複数ファイル・複数投稿を、対象ユーザー単位で一つに統合。
-
処理対象:1日最大40件投稿(例:@anti-ygpgsgl のような大量投稿アカウント)。
-
対応形式:HTML / JSON / スクリーンショットからの文字起こし対応済み。
3. 話術テンプレート抽出モジュール
ワード頻度ではなく、“構文の暴力性”を判定軸とする独自ロジックを採用。
-
英語パターン例:you’re AI / seek therapy / this is so embarrassing / stop pretending など。
-
検出単位:1フレーズでもアウト。頻出かどうかは補助的情報として扱う。
-
目的:言語の表層ではなく、その背後にある構造的な攻撃意図の可視化。
4. 絵文字分類モジュール(試作中)
💀👅🎉😒👍😈 など、文脈依存性の高い絵文字を「挑発」「冷笑」「侮辱」の3カテゴリに分類。
-
対象:LadyYomi など、投稿ごとに絵文字を頻繁に用いるユーザー。
-
判定基準:絵文字単体 + 文脈ペア + 対象ユーザーの投稿傾向による統合的判定。
-
補足:分類結果は、視覚化/ユーザー別スコアリングに活用予定。
5. 画像検出補助モジュール(開発中・課題あり)
-
原作CGを改変し、「seek therapy」などの侮蔑的メッセージを合成した画像(例:風間CGのパロディ)を検出対象とする。
-
検出された画像内の文言や構図情報は、擬似的にテキスト化され、他の文章モジュールと同様に統合処理される。
-
処理手順:
-
メタ情報の照合
-
OCRによる文字検出
-
既知のテンプレート画像リストとの比較
-
-
現状:改変の巧妙化により、人力判定との併用が必要な段階。
6. 統計・可視化モジュール(最終出力系)
各種モジュールから送られたラベル情報・検出結果を、投稿単位で集計・可視化。
1投稿につき1カテゴリ1カウントのルールを適用し、過剰集計を防ぐ。
-
集計対象項目:
-
カテゴリ別出現件数(ラベルごとの分布)
-
タイムライン(時間帯別の出現傾向)
-
ユーザー別投稿件数(攻撃集中度)
-
代表的フレーズ・テンプレート事例
-
絵文字・画像モチーフの分布傾向(予定)
-
-
出力形式:
-
JSON / CSVファイル(分析用)
-
ラベル別ヒートマップ・ユーザー別トレンドチャート
-
「〇月〇日:AIステマ攻撃集中」「特定ユーザーによる風間侮辱パロディ集中」などの可読性重視の週次報告用可視化出力
-
-
特徴:
-
ラベルが付与されていない投稿(=0件)も明示的にカウントされる
-
ラベルの複数同時命中も認識(ただし各カテゴリで1回のみカウント)
-
※ なお、加害者は英語だけでなく、中国語での家族や文化への侮辱的な発言も行っていた。そのため、本システムでは多言語対応型の構文検出ルールを採用している。
7. SNS横断型 文体・語用モジュール(草案)
同一ユーザーによる複数SNS上の投稿(AO3・Tumblr・Discord・X等)における文体・語調・語彙選択の差異を比較し、「書き手の演技性」や「暴力的構文のカモフラージュ傾向」 を定量化する試み。

図 2:ターゲット例(ayws型)
🧩 分析項目(分析対象になる文体指標):
-
絵文字・感嘆詞・語尾の柔らかさ
-
“I think” “just” “maybe” の使用頻度
-
ネットスラングと文章句読の混在率
-
自己言及 vs 他者命令文の比率
🌈 利用目的:
-
「誰がどこでどんな顔をしているのか」を構文上から見抜く
-
特定投稿が「本心」か「仮面」かを語用論的に照射する
-
最終的には「SNS上における演技人格シミュレーター」になるかも(やり過ぎか?w)
※このモジュールは最も公開用資料に近く、外部との共有・報道支援時の中核的機能を担う。
⚠️ 設計ポリシーと制約
-
本プロトコルは英語圏SNS(Tumblr、X、AO3など)での使用を想定している。本システムはあくまで構文・視覚情報ベースの判断に特化しており、リプライ文脈や皮肉の高度な文体変換には未対応。また、日英中のミックス表現や、自動翻訳による意味変容への耐性は今後の課題である。
- 本システムでは、英語以外の言語で記載された攻撃文(特に中国語の罵倒語)についても、文化的侮辱・家族に対する誹謗中傷として構文認定される。
-
本稿は、筆者自身が経験した構造的ハラスメントに対応するため、その記録・検出・可視化を目的として開発中のシステムについてまとめたものである。現時点では、本システムはあくまで個人利用を前提とした非公式プロトコルであり、企業向け・信頼安全部門向けの製品開発は想定していない。
-
本プロトコルは、AIの生成モデルに依存した解析を行うが、いわゆる“AI幻覚”の影響を最小限に抑えるため、以下のような対策を推奨する。
-
高重要度タスクに対しては、複数の言語モデル(例:OpenAI + Claude)によるクロス検証を実施。
-
システムによるタグ付け・構文分類の結果は、出力ソース別にログ記録し、検証可能性を確保する。
-
モデルの回答をそのまま“事実”と見なすのではなく、入力構造と照合しながら二重チェックを行う姿勢を前提とする。
-
※ 経済的支援のない立場から、無料リソースと最小限のAPI利用で構築。誤った自動判定による誹謗・レッテル貼りのリスクを回避するためにも、特に外部公開・報告用には慎重な検証が必要です。
本稿は、筆者個人が構築した構文型ハラスメント記録支援システムのα版記録である。
それ以上でも、それ以下でもない。
💬 結語
私は官僚が自発的に私を守ってくれるとは、これまで一度も期待したことはありません。もし、あのときE FFやAccess Nowのような国際団体にすべての希望を託していたら、今ごろ私はとっくに終わっていただろう。
信じてください、私が助けを求めた方法はあなたが想像するよりずっと多いです。しかし私はまるでピンポン玉のように、さまざまな地域や組織、部署の人々に蹴り回されてきました。そこには私の「偉大な祖国」や「親愛なる同胞」も含まれます。
だから、私は自ら証拠システムを構築したのです。
これは、放置された暴力に対して個人が挑んだ、構文的サバイバルログである。“記録されなかった言葉”を、記録するために私はここにいる。
もし本件に関するさらなる情報提供を希望する報道関係者がいれば、E FFやAccess Nowとの実際のやりとりを含む資料の提供も可能です。
(※メディア関係者のみ、お問い合わせはメールにて)
嫌がらせ行為者およびその関係者は遠慮するように。一度連絡してきた場合は、ブラックリストに登録し、スクリーンショットを証拠として保存する。このnoteアカウントを集団で通報しようとしても無駄です。各記事はすべて私がバックアップしています。